
Big Data Mixtape
I grew up within receiving distance of the radio waves of KSHE-95; the country’s oldest FM rock-n-roll radio station. It was my favorite radio station throughout high school and my source for more than a few mix tapes. This was before Spotify, Napster, or even the modern Web as we know it. In fact, not all of my friends even had a computer in their house yet. If you wanted to copy and share music with friends, you had to do it on cassette tapes. I particularly liked to listen to the Monday Night Metal show every Tuesday night on KSHE.
The DJ would play new albums in their entirety without any breaks, which makes for the perfect opportunity to “download” a new album for free. I would have a blank Maxell tape loaded with the record button down and my finger on pause just waiting for the right moment. This is how I obtained my first copy of Metallica’s The Black Album. It may be hard to believe now because Metallica is nearly a household name, but before their seminal Black Album it was rare to hear their music during the day on the airwaves. I don’t remember Lars Ulrich complaining much back then about people recording to cassettes from the radio and sharing with their friends to build their fan base.
Over the years my music collection evolved from Cassette Tapes to CDs. I even acquired a 200 disc CD changer prior to ripping them all to MP3 files. As I think about the progression of various media I’ve used to store my music collection over the years, I’m reminded of the various types of data storage solutions that we have choose from when architecting a data solution. The medium you choose tends to be influenced by how you intend to listen to the data.
Some albums, like Led Zeppelin’s second album, just beg to be listened to from start to finish. I still get frustrated when I don’t hear Livin’ Lovin’ Maid immediately follow Heartbreaker when it’s played on the radio. Sometimes, it is best to listen to your data sequentially too. This is most common when you have a continuous stream of data and you want to do some processing on it. If you “listen” to a stream of clicks on a website, you can count the number of clicks every second and update a dashboard in real-time.

These streams of data can best be thought of as logs. In fact, the best blog I have read on this is Jay Krep’s article: The Log: What every software engineer should know about real-time data’s unifying abstraction. Jay was one of the principal engineers behind the creation of Apache Kafka whilst at LinkedIn and has since cofounded Confluent to offer a commercial version of software. Apache Kafka is one of the most popular methods to handle the sequential storing and retrieval of data at scale. In fact, the Kafka clusters at Linked in handle hundreds of terabytes of data every day.
A message queue provides a buffer between the system producing the data and the downstream processes that consume it. This buffer becomes important when your consuming system(s) cannot process at the same rate as the data is being produced. If you can scale up your downstream process, then you can increase the rate at which you consume the data. When I used to record music from the radio onto a cassette tape, I was limited by how quickly the music was broadcast over the air. However, whenever I wanted to make a copy for a friend, I could use high-speed dubbing to make a copy on my stereo in about half the amount of time. If you are considering implementing a streaming data solution, you may want to explore some kind of message queue to sequence the data and decouple it from the producers and consumers.
Some albums, and even some artists, don’t beckon to have their entire catalog digested from start to finish. When Pearl Jam came out with Ten, I became an instant fan and bought each new CD they released thereafter. Their B-Sides like Yellow Ledbetter were sometimes better than other bands’ A-Sides. However, by the time I picked up their Yield album, I found myself skipping through tracks.
Likewise, if you know exactly which piece of data you want to access quickly, you should consider a key-value store. I knew that if I entered a “key” of 4 after popping in the Pearl Jam’s Yield CD, I would instantly start hearing Given to Fly. When I later entered the album into slot 125 of my CD changer, my “key” became a little bit longer, 125-4. I could still get to the same song even though it was part of a much larger collection. This is the same concept typically used when utilizing a key-value store. The key can have any number of items concatenated together to make it unique.
There are no shortage of key-value stores to choose from. Some of the more popular open source options are Aerospike, Redis, and Riak. A key-value store has no knowledge of what kind of data resides within the “value”, so the responsibility is on the application to know how to interpret the content.
About the same time that my CD collection was outgrowing the limits of my 200 disc changer, I discovered Winamp and MP3 files. One of the great things about MP3 files is that you can record all of the metadata about a song (Artist Name, Album Name, Genre, Year Released, Rating, etc.) in the same file as the audio itself. This allowed me to quickly search the Hair Metal genre and get all of my favorite songs by Cinderella, Def Leppard, Motley Cruë, Poison, Warrant (the list goes on). Essentially, I was doing a reverse lookup on the “values” to retrieve a set of “keys.”
If you need to be able to query your data by some of the entries in the “value”, then you should look at a document data store. These are essentially key-value stores where the “value” has structured data (think JSON or XML) that can be indexed for such queries. The popular open source options in this area are Couchbase, CouchDB, Elasticsearch and MongoDB.
You might be thinking that you don’t need a document data store to create indexes for reverse lookups, because Relational Database Management Systems (RDBMS) like MySQL and Postgres have already been doing this for years. You would be correct too. However, one of the main differences between a document data store and an RDBMS is that the document data store enforces a schema on read, whereas an RDBMS enforces a schema on write. If you decide to start adding another piece of data, such as Mood, you can do so at runtime without invalidating all the documents that came before it. In an RDBMS however, you would need to add a new column to the table’s schema before writing any data to it. Conversely, one benefit that an RDBMS has, which tends to be lacking in key-value and document data stores, is strict ACID compliance.
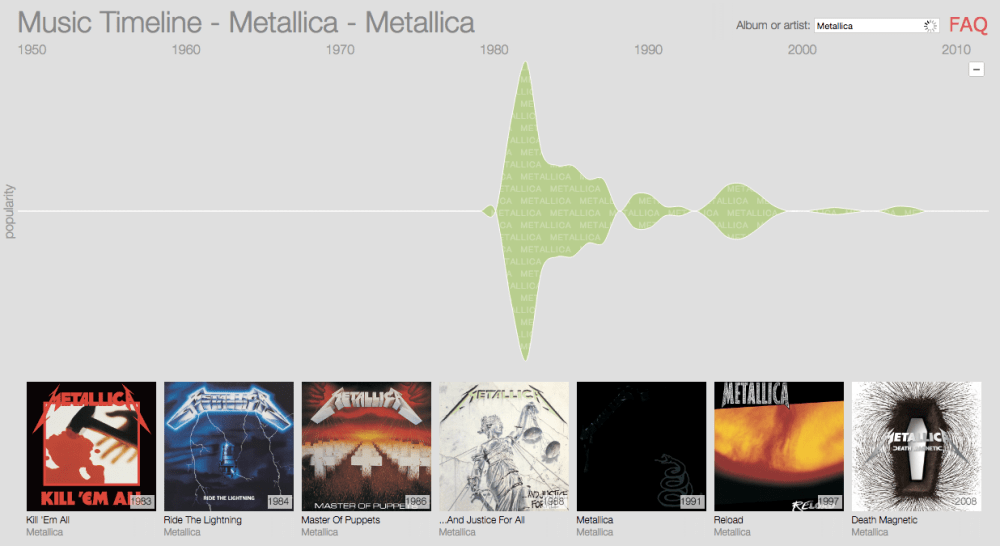
So far, all of these examples have been about how I can listen to an individual song, or a set of songs. However, I may want to gleam some insight across my entire music collection. Google has created the Music Timeline to visualize the popularity of various music genres from the 1950s onward. Search for an individual artist to map their popularity over time.
Whenever you need to group large amounts of data with aggregate functions, such as sum() and avg(), you will benefit from using a columnar data store or columnar data format. These data stores are optimized to answer these kinds of summation queries. The two most popular open source data formats are Parquet and ORC. These files can be easily ingested by query engines such as Spark SQL or Hive. Alternatively, you may seek to use a columnar data store such as the open source Greenplum.
Through the years, my music library has grown and transitioned from cassette tapes to CDs to MP3s (and even a brief flirtation with MiniDisc). Likewise, the architecture I have deployed for data solutions has transitioned quite a bit from a standard RDBMS. There is no wrong way to listen to your music, or your data. Different methods of accessing your collection lend themselves to different mediums, and there’s no shame in duplicating your data across different stores to optimize for different access patterns. Sometimes you start with one medium and outgrow it for another. In that spirt, Lars Ulrich will be reassured to know that I did eventually buy The Black Album; on both cassette and CD:)



